AI 에이전트의 '금붕어 기억력' 문제
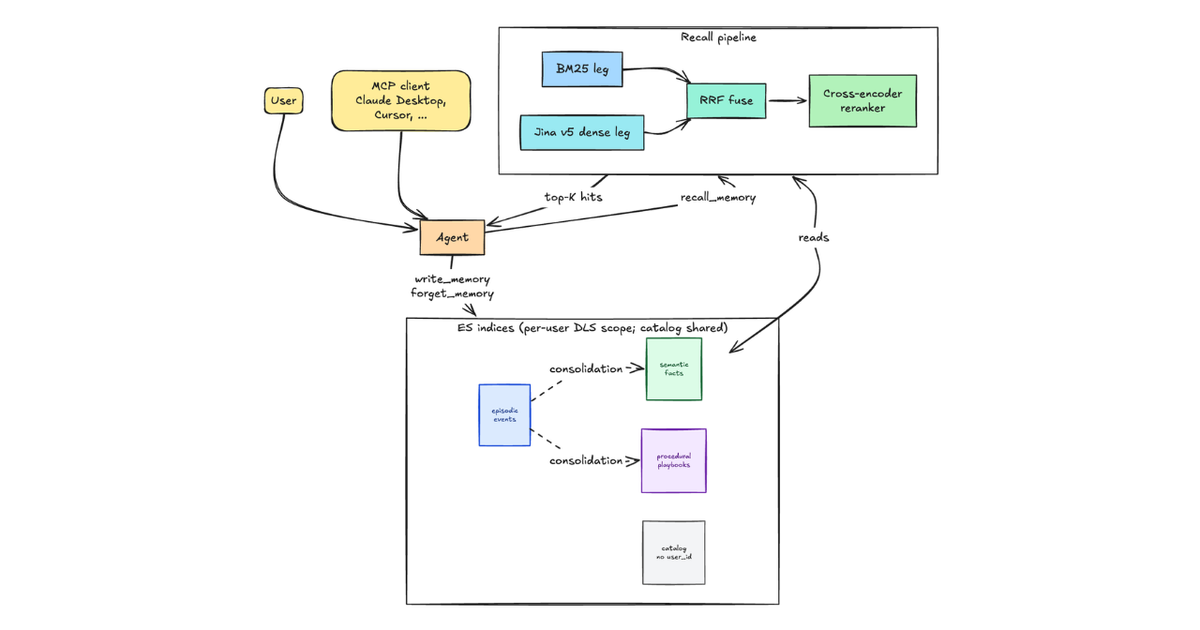
요즘 LLM으로 에이전트 한번 만들어 보신 분들은 다들 한 번쯤 답답함을 느끼셨을 거예요. 대화를 아무리 길게 나눠도 세션이 끝나거나 컨텍스트 창(모델이 한 번에 볼 수 있는 토큰 양이에요)이 꽉 차면, 방금 한 얘기를 통째로 잊어버리거든요. 딱 금붕어 같죠. 그래서 에이전트한테 '장기 기억'을 붙여주는 게 요즘 큰 숙제인데, Elastic이 이걸 Elasticsearch 위에서 구현하고 재현율(recall) 0.89를 달성했다는 글을 냈어요.
recall 0.89가 무슨 뜻이냐면
먼저 recall부터 풀어볼게요. recall(재현율)은 '찾아와야 할 정답이 10개 있었는데 그중 몇 개를 실제로 가져왔나'를 재는 지표예요. 0.89면 관련 기억의 89%를 놓치지 않고 끌어왔다는 뜻이죠. 이게 왜 중요하냐면, 과거 기억 중에 지금 질문과 관련된 걸 빠뜨리면 에이전트가 엉뚱한 소리를 하니까요. 기억을 '저장'하는 것보다 사실 '잘 꺼내오는' 게 더 어려운 일이거든요.
핵심은 Elasticsearch의 하이브리드 검색이에요. 키워드 매칭(BM25)과 의미 기반 벡터 검색을 합치는 거죠. 풀어서 설명하면, 벡터 검색은 '비슷한 의미'를 잘 찾아오고 키워드 검색은 '정확히 그 단어'를 잘 찾아와요. 둘은 서로 약점이 다른데, 점수를 합쳐서(RRF 같은 방식으로) 같이 쓰면 약점을 메워줘서 recall이 확 올라가요. 게다가 대화를 통째로 박아넣는 게 아니라, 요약하고 사실 단위로 쪼개서 저장하는 파이프라인을 같이 쓰는 게 포인트예요.
업계 맥락 — 전용 메모리 도구 vs 기존 검색엔진
에이전트 메모리 영역엔 이미 mem0, Zep 같은 전용 라이브러리, 그리고 Pinecone·Weaviate·Qdrant 같은 벡터 DB들이 경쟁 중이에요. 이들은 메모리에 특화돼서 깔끔하지만, 새 인프라를 또 하나 들여놓아야 한다는 부담이 있죠. Elastic의 접근은 결이 달라요. '너희 이미 로그랑 검색용으로 Elasticsearch 쓰고 있잖아? 그럼 그 위에 메모리도 얹어' 하는 거예요.
한국 개발자에게
국내에 ELK 스택(Elasticsearch+Logstash+Kibana)을 굴리는 회사가 정말 많거든요. 로그 분석이나 사내 검색 때문에요. 그렇다면 에이전트 메모리를 위해 벡터 DB를 새로 도입하는 대신, 익숙한 Elasticsearch를 그대로 재활용하는 선택지가 생기는 거예요. 운영 노하우, 권한 관리, 백업 정책이 다 그대로 쓰이니까 도입 장벽이 훅 낮아져요.
마무리
핵심 한 줄: 에이전트의 기억은 결국 '검색 문제'이고, 잘 다루던 검색엔진을 재활용하는 게 의외로 현실적인 답일 수 있다는 거예요. 여러분이라면 깔끔한 전용 메모리 도구를 새로 쓰시겠어요, 아니면 이미 운영 중인 Elasticsearch를 확장하시겠어요?
🔗 출처: Hacker News

"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공